KAFKA安装
简介
Kafka是由Apache软件基金会开发的一个开源流处理平台,由Scala和Java编写。该项目的目标是为处理实时数据提供一个统一、高吞吐、低延迟的平台。其持久化层本质上是一个“按照分布式事务日志架构的大规模发布/订阅消息队列”,[3]这使它作为企业级基础设施来处理流式数据非常有价值。此外,Kafka可以通过Kafka Connect连接到外部系统(用于数据输入/输出),并提供了Kafka Streams——一个Java流式处理库 (计算机)。该设计受事务日志的影响较大。
历史
Kafka最初是由领英开发,并随后于2011年初开源,并于2012年10月23日由Apache Incubator孵化出站。2014年11月,几个曾在领英为Kafka工作的工程师,创建了名为Confluent的新公司,[5],并着眼于Kafka。根据2014年Quora的帖子,Jay Kreps似乎已经将它以作家弗朗茨·卡夫卡命名。Kreps选择将该系统以一个作家命名是因为,它是“一个用于优化写作的系统”,而且他很喜欢卡夫卡的作品。
Kafka架构
Kafka存储的消息来自任意多被称为“生产者”(Producer)的进程。数据从而可以被分配到不同的“分区”(Partition)、不同的“Topic”下。在一个分区内,这些消息被索引并连同时间戳存储在一起。其它被称为“消费者”(Consumer)的进程可以从分区查询消息。Kafka运行在一个由一台或多台服务器组成的集群上,并且分区可以跨集群结点分布。
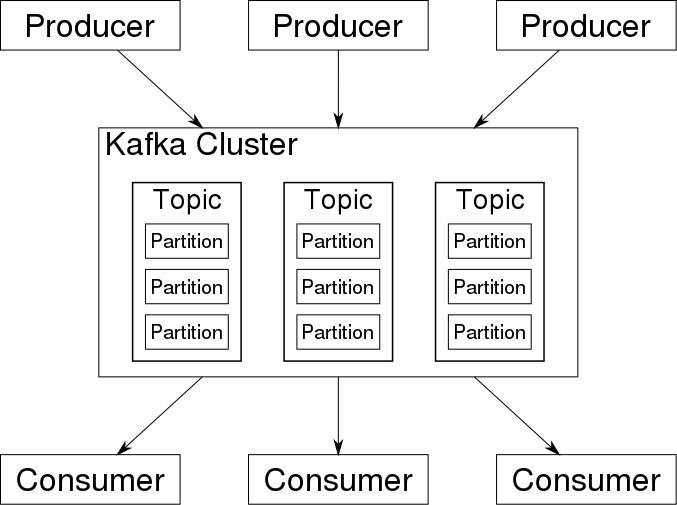
-
生产者API:支持应用程序发布Record流。
-
消费者API:支持应用程序订阅Topic和处理Record流。
-
Stream API:将输入流转换为输出流,并产生结果。
-
Connector API:执行可重用的生产者和消费者API,可将Topic链接到现有应用程序。
安装
我这边的安装环境是CentOS 7,JDK8环境。根据不同环境更改即可。
安装JDK
到oracle官网下载,地址:
找到64位的RPM文件,下载,然后sftp传到要安装的机器上,也可以使用wget直接下载
安装
rpm -ivh jdk_xxx.rpm
安装完还需要配置JAVA_HOME,可以参考
下载安装KafKa
解压安装
tar zxvf kafka_xxx.tgz mv kafka_xxx kafka cd kafka
功能验证
1.启动Zookeeper
使用安装包中的脚本启动单节点Zookeeper 实例:
bin/zookeeper-server-start.sh -daemon config/zookeeper.properties
2.启动Kafka 服务
使用kafka-server-start.sh 启动kafka 服务:
bin/kafka-server-start.sh config/server.properties
3.创建topic
使用kafka-topics.sh 创建单分区单副本的topic test:
bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic test
查看topic:
bin/kafka-topics.sh --list --zookeeper localhost:2181 test
4.产生消息
使用kafka-console-producer.sh 发送消息:
bin/kafka-console-producer.sh --broker-list localhost:9092 --topic test
Hello world!
Hello Kafka!
5.消费消息
使用kafka-console-consumer.sh 接收消息并在终端打印:
bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic test --from-beginning
6.其他功能:
设置保留时间(默认保留)
如果您需要删除主题中的所有消息,则可以利用保留时间。首先将保留时间设置为非常低(1000 ms),等待几秒钟,然后将保留时间恢复为上一个值。
注意:默认保留时间为24小时(86400000毫秒)。
bin/kafka-configs.sh --zookeeper localhost:2181 --alter --entity-type topics --entity-name test_topic --add-config retention.ms=100000
集群配置
修改zookeeper配置
使用kafka自带的zookeeper,切换到kafka目录,修改zookeeper配置文件
vim config/zookeeper.properties
在 每台机器上, 的配置文件下增加了最后 5 行配置:
ticketTime=2000 clientPort=2181 dataDir=/opt/zookeeper/data dataLogDir=/opt/zookeeper/logs initLimit=10 syncLimit=5 server.1=master:2888:3888 server.2=slave01:2888:3888 server.3=slave02:2888:3888
配置说明:
-
集群模式中, 集群中的每台机器都需要感知其它机器, 在 zookeeper 配置文件中, 可以按照如下格式进行配置, 每一行代表一台服务器配置:
server.id=host:port:port
id 被称为 Server ID, 用来标识服务器在集群中的序号。
注意:对于每台 ZooKeeper 服务器上, 都需要在数据目录(即 dataDir 指定的目录) 下创建一个 myid 文件, 该文件只有一行内容, 即对应于每台服务器的Server ID。
-
ZooKeeper 集群中, 每台服务器上的zookeeper 配置文件内容一致。
-
server.1 的 myid 文件内容就是 "1"。每个服务器的 myid 内容都不同, 且需要保证和自己的ZooKeeper配置文件中 "server.id=host:port:port" 的 id 值一致。
-
id 的范围是 1 ~ 255。
###创建myid文件 在 dataDir 指定的目录下 (即 /opt/zookeeper/data 目录) 创建名为 myid 的文件, 文件内容和ZooKeeper中当前机器的 id 一致。根据上述配置, master 的 myid 文件内容为 1。
配置kafka集群的信息
分别修改每台机器的配置文件
vim config/server.properties
# The id of the broker. This must be set to a unique integer for each broker. broker.id=120 zookeeper.connect=192.168.20.120:2181,192.168.20.121:2181,192.168.20.122:2181
broker.id也需要改为不一样
启动zookeeper:
bin/zookeeper-server-start.sh -daemon config/zookeeper.properties
对应的关闭zookeeper
bin/zookeeper-server-stop.sh
kafka 服务
bin/kafka-server-start.sh config/server.properties
启动一个生产者
bin/kafka-console-producer.sh --broker-list 192.168.20.120:9092,192.168.20.121:9093,192.168.20.122:9094 --topic my-replicated-topic
如果需要外部访问,还需要进行配置
1.配置防火墙,开放对应的端口
2.配置服务器的访问地址不是localhost
修改 kafka/config/service.properties 中的 advertised.host.name=<远程kafka服务器的ip地址>
ref:
https://www.mtyun.com/library/how-to-install-kafka-on-centos7
https://blog.csdn.net/isea533/article/details/73720066
欢迎关注我公众号:
